
Before giving reasons to why you should care about hashes and hashing, let’s ensure a common understanding. In simplest terms, hashing is a mathematical operation that gives a unique output (the hash) based on an input. Most important, and why it is widely used for purposes of information integrity, is that even the most minute change in the input will drastically change the output. Another important trait about the operation is its one-way nature, meaning you cannot reverse it. Alternatively stated, you cannot determine the input from the output alone. Let’s explore why these two traits are important and ultimately are the reasons you should care about it.
Let’s start with information integrity that I briefly mentioned. Integrity is part of the CIA triad. No, not the CIA as in the three-letter government agency (although if it helps to remember, you’re welcome!). Confidentiality, Integrity and Availability – the cornerstone of information security. I would go a bit further and state that CIANA is the expanded version, the N and A standing for non-repudiation and accounting, but that is a topic for a different post. Fundamentally, integrity is ensuring that any given piece of information or data has not been altered in any way. A common way of verifying integrity is to use hashing. Recall I stated that hashing takes an input to generate a unique output? The input has no constraint (that I’m currently aware of) and can be as simple as a blank .txt file, or can be as large as a 10TB disk image file. Hashes can be generated for both of those examples. When I was learning this concept, the association that helped me was to equate hashing with integrity.
Allow me to demonstrate the two important traits of a hash, using functions built into Windows. You can try these as well without the need to do anything more than open your command prompt.
Two important traits of a hash:
- Any change in the input equals to a LARGE change in the output.
- The output is unique to the input (think digital fingerprint) and cannot be used to determine the input alone.
Let’s start with the 1st trait. For this example, I created a directory on my hard drive, and created a blank text file:
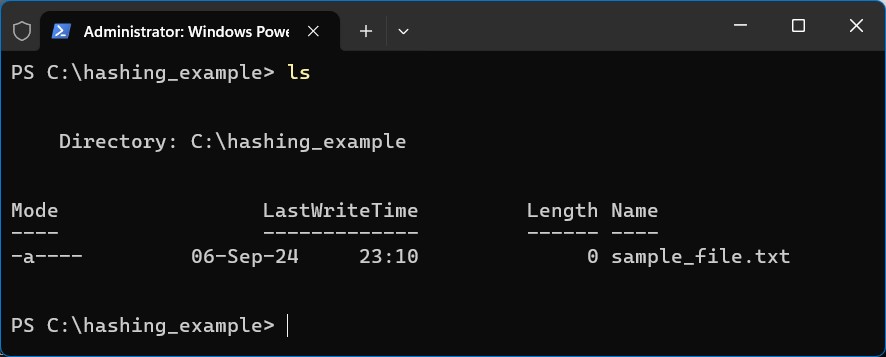
I then opened the text file and added text to it:
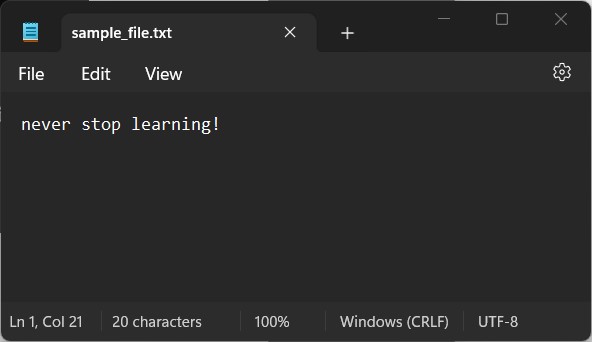
With that saved, let’s check the file one last time:
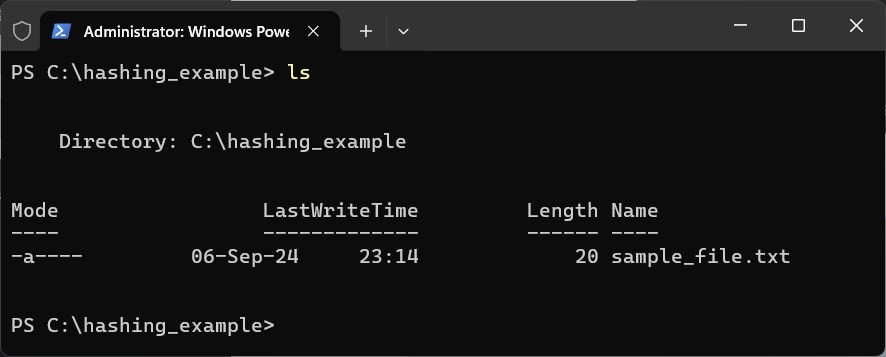
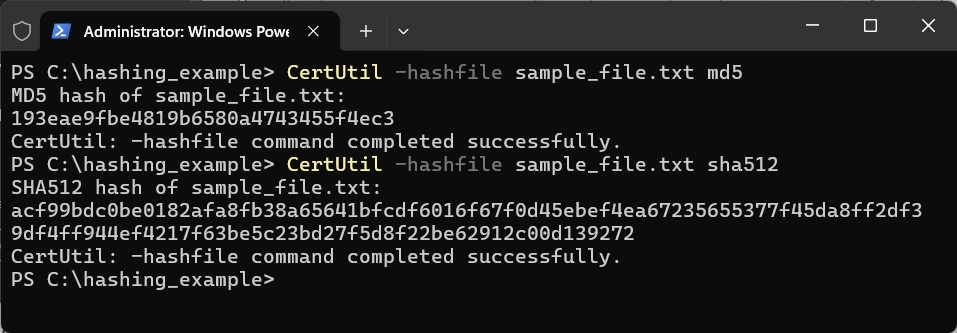
Let’s compute a hash using the CertUtil function, utilizing two well-known algorithms – MD5 and SHA512. One important note about hash algorithms is that each has a set length for the output. For example, MD5 has an output length of 128-bits (represented in the following image by 32 hexadecimal characters), whereas SHA512 has an output length of 512-bits (represented by 128 hexadecimal characters). The longer the output, the more meaningful it becomes and less susceptible to cryptographic attacks (more on this when we discuss the second trait).
Let’s change one thing about the contents of the text file. I changed from a lowercase s to a capital S as follows:
Finally, let’s compute hashes of the change:
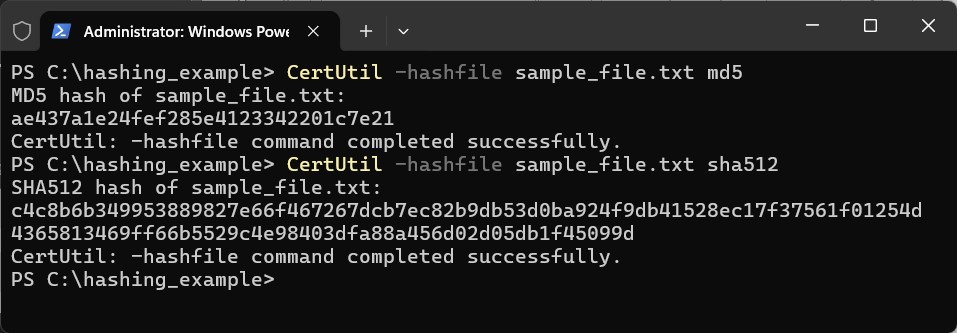
And summarize:

I hope this demonstrates that for a change as simple as capitalizing one letter, the hash (also called the digest) is as different as day is to night. Because of the set output length of each algorithm, comparing them to draw meaningful conclusions is possible.
Lastly, let’s briefly take a detour and discuss the second trait. The output is unique to the input, much like a digital fingerprint, and cannot be used to determine the input alone. As the power of computers grows with advancements in technology and manufacturing, so too does compute power. Cryptographic functions, like hashes and other encryption algorithms, rely largely on the computational power needed to decrypt it, when you do not possess the decryption key. Simply stated, with enough time, encryption can be broken via brute force or other methods. It’s strength comes in the form of how quickly that can be accomplished, or lack thereof. Furthermore, attempting to do so in near real-time is nearly impossible. One huge caveat to that is with the rise of quantum computing, but that too is another topic entirely. Back to the point. Hashing also does possess weaknesses. Mainly, in its output length. Overtime the output length has gotten longer to keep up with the compute capabilities of modern computers. There is one term I’d like to bring up, and that is of collision. A collision in the context of hashing means that there exists two different inputs, which produce the same output. This is contrary to what I described, in that for any input a unique output exists. This is largely true, and collisions are rare. But not impossible. It is one of the main reasons that hashing algorithms evolve and become more complex with greater length outputs. Imagine the chaos that ensues when you’ve built modern security systems on this principle of integrity, with the underlying principle that for any input there exists one unique output. Suddenly, it is discovered that there are instances where two inputs can produce the same output. That is what collisions can cause. It fundamentally crumbles the underlying logic. Now, back to the main point.
Having shown a simple example of hashing, we can now get to why this is so important and underpins many of the modern information security features. Hashing is a repeatable and exact way of verifying integrity. Here are examples of ways hashing is used:
- Digital signatures. Email can use this feature to compute a hash of the email message, encrypt the hash using your private key, allowing anyone with your public key to decrypt and verify the message has not been altered.
- Password storage. Websites often store your username and password credentials in a database. When you attempt to login to the site, it compares your inputs to that of the database to authenticate you. The passwords are NOT stored as plain text (hopefully), but instead as hashes. Remember the important trait of hashes and it being a one-way function? This is why passwords are stored as hashes.
- One note about storing hashes of passwords. Recall earlier the explanation of collisions and the havoc it can cause. If someone were to gain access to and steal the hash of your password, it’s almost as good as the password itself. The attacker would still need to decipher it, but exploiting the concept of collisions could help. They do not necessarily need to figure out your password, but instead find a combination of characters that when the hash is computed, match the hash of your actual password. Yet another reason why collisions are very bad news, and why short-length output hash algorithms such as MD5, are NOT recommended for use.
- File downloads. You may have seen some websites display a “checksum” when downloading a file. This checksum is a hash (they need to state the algorithm used) and you can use it to determine if the file has been altered. You can use the CertUtil function in the Windows command prompt to calculate the hash and compare it to the checksum.
- File Integrity Monitoring. A common technique for monitoring critical system files in near real-time. How is that accomplished? The program will constantly calculate hashes of these files and compare it to a “known good state”. Any deviation from this state will then trigger an alert or subsequent action.
- Digital Forensics. Integrity is critical to forensics, especially with data or information that will be admissible evidence in court. As such, hashing is very commonly used in forensics to ensure the integrity of digital evidence. Specifically, that it has not been altered through the process of examining the evidence for wrongdoing. Investigators can also use known hashes of known malware or a myriad of other objects of interest, to aid in searching for evidence.
This post is only a small portion of the deep rabbit hole you can go down when learning about hashing. With this information, you should have a better understanding of the tremendous importance hashing plays in the world of information security, and the role it plays in ensuring data integrity.